
Defect Clustering Explained
The 80/20 rule in software quality

Welcome back to NextGen QA! In our previous article, we explored why exhaustive testing is impossible and how risk-based testing helps us focus effort strategically. Today, we’re diving into a phenomenon that makes risk-based testing even more powerful: defect clustering.
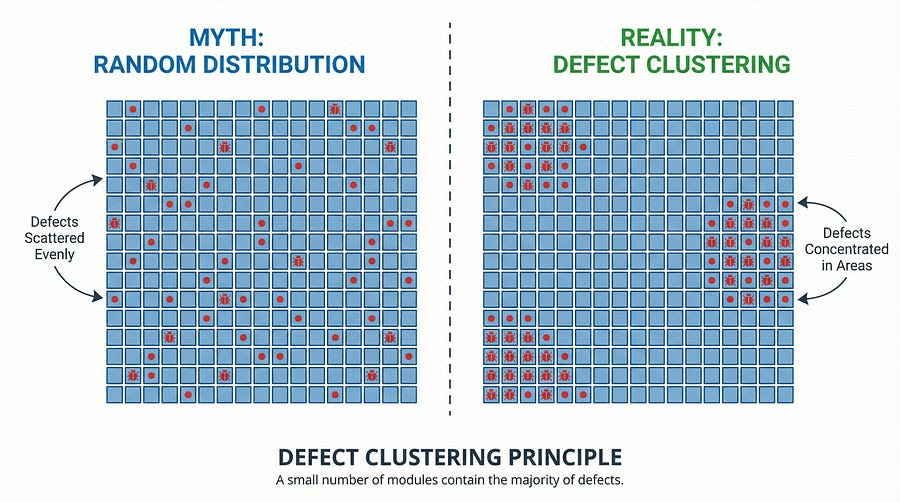
Here’s a pattern that every experienced tester has witnessed: bugs don’t distribute evenly across your codebase. They cluster together in specific areas, like bees around a hive. Understanding this pattern transforms how you approach testing.
Let’s explore why defects cluster, how to identify clusters, and what to do when you find them.
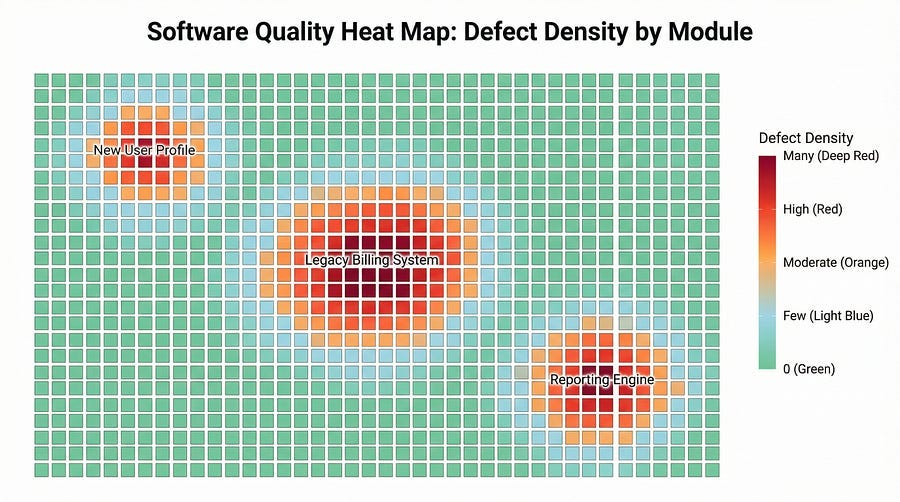
The Pareto Principle in Software Testing
The phenomenon of defect clustering is often called the Pareto Principle or the 80/20 rule when applied to software quality. The concept is simple but profound: approximately 80% of defects are found in 20% of modules.
This isn’t just a convenient approximation. Study after study across different organizations, projects, and industries consistently shows this pattern. Microsoft analyzed defects across Windows and found that a small percentage of files contained the vast majority of bugs. IBM’s research showed similar clustering in their projects. Open-source projects demonstrate the same pattern when you analyze their bug repositories.
The exact ratio varies by project — sometimes it’s 70/30, sometimes 90/10 — but the principle remains constant: defects concentrate in predictable areas rather than distributing randomly.
Why This Matters
Understanding defect clustering changes everything about how you test. Instead of spreading your testing effort evenly like peanut butter across toast, you can target your efforts where they’ll find the most defects. It’s the difference between searching randomly for gold and knowing which hills contain the richest veins.
When you find one bug in an area, you should immediately think: “Where are this bug’s friends?” Because they’re almost certainly nearby.
Why Defects Cluster Together
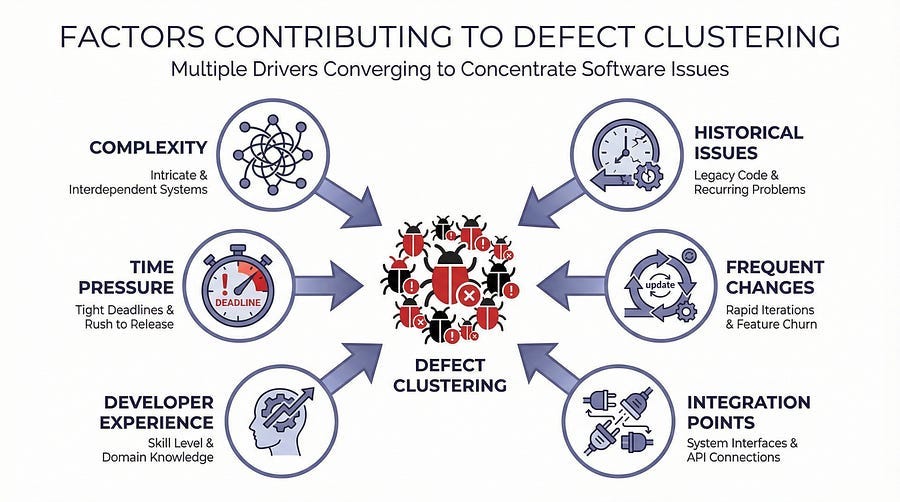
Defect clustering isn’t random — there are specific, identifiable reasons why bugs congregate in certain areas.
Complexity Breeds Defects
The most common reason for defect clustering is complexity. Complex code with intricate logic, multiple conditionals, nested loops, and intertwined dependencies creates more opportunities for errors. A simple function with straightforward logic might have zero defects. A complex algorithm with fifteen edge cases and seven integration points might have twenty defects.
Think of it like a highway system. A straight country road rarely has accidents. A complex interchange with multiple merging lanes, exits, and traffic patterns becomes an accident hotspot. The complexity itself creates risk.
Historical Problem Areas Remain Problematic
Software has memory — not in RAM, but in its structure and history. Areas that have been buggy in the past tend to remain buggy in the future. This happens for several reasons. The underlying complexity that caused original bugs usually remains. Quick fixes and patches often add more complexity without addressing root causes. Developers become hesitant to refactor problem areas for fear of breaking things further, creating a vicious cycle. Technical debt accumulates as teams prioritize new features over fixing foundational issues.
Once an area becomes known as “the problematic module,” it often stays that way for years unless someone makes a concerted effort to refactor and improve it.
Change Introduces Defects
Areas of code that change frequently tend to have more defects than stable code. Every modification introduces risk. Even experienced developers make mistakes when changing code. Integration between new and old code creates seams where bugs hide. Regression defects appear when changes inadvertently affect existing functionality.
If you track where code changes happen most frequently, you’ll often find it correlates strongly with where defects cluster.
Integration Points Are Vulnerable
Defects love boundaries. The places where different systems, components, or modules meet become natural clustering points for bugs. When two teams build different parts that must communicate, assumptions don’t align. Data format mismatches cause errors. Timing and synchronization issues arise. Error handling gets overlooked at boundaries. Each side assumes the other side will handle certain scenarios.
API endpoints, database interfaces, third-party service integrations, and module boundaries all become defect magnets.
Developer Experience Varies
This is uncomfortable to discuss but important to acknowledge: defect clustering often correlates with who wrote the code. Less experienced developers naturally produce code with more defects as they learn. Developers new to a technology or framework make mistakes that experienced developers avoid. Different developers have different strengths — someone excellent at algorithms might struggle with user interfaces.
This isn’t about blame — it’s about understanding patterns so you can provide appropriate support, code review, and testing.
Time Pressure Creates Debt
When deadlines loom and pressure mounts, quality suffers in predictable areas. Features developed during crunch time have more defects than those built with adequate time. Code written at the end of sprints when teams are rushing tends to be buggier. Corners get cut — testing gets skipped, error handling gets deferred, edge cases get ignored. The pressure creates technical debt that manifests as defect clusters.
If you map development timelines against defect locations, you’ll often see spikes corresponding to high-pressure periods.
Identifying Defect Clusters in Your Project
Recognizing where defects cluster requires systematic observation and data analysis.
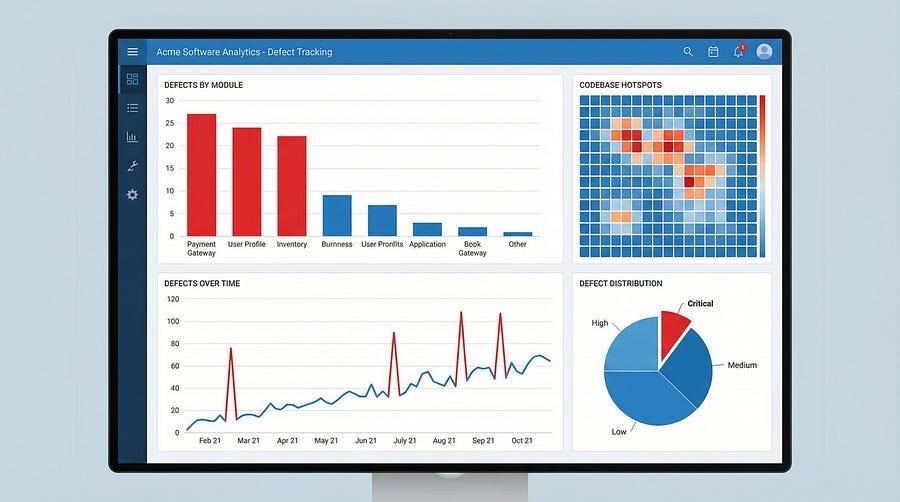
Track Defects by Module
The simplest approach is maintaining a defect tracking system that categorizes bugs by component, module, or feature area. After a few weeks or months of testing, patterns emerge clearly. You might discover that your user authentication module has logged thirty-seven defects while your settings page has logged three. That’s a cluster.
Create a simple spreadsheet or use your bug tracking tool’s reporting features to count defects by area. Sort by count. The clusters will be obvious.
Monitor Code Churn
Code churn refers to how frequently code changes. High churn correlates strongly with defects. Tools like Git can show you which files or modules change most frequently. Compare this against your defect data. You’ll likely find significant overlap between high-churn areas and high-defect areas.
If a particular file has been modified in seventy-five commits over the past month while other files have been touched five times, you’ve found a potential cluster zone.
Analyze Code Complexity Metrics
Various tools can calculate code complexity metrics like cyclomatic complexity, which measures the number of independent paths through code. Higher complexity scores predict higher defect rates. Run complexity analysis on your codebase and compare results against actual defect data. The correlation will likely surprise you with its strength.
You don’t need to understand all the mathematical details of complexity metrics to use them. Just look for the numbers that stand out as unusually high.
Review Production Incidents
Don’t just track testing defects — track production incidents too. When things break in production, where do they break? Which services or modules cause the most customer-facing issues? Production incident patterns often reveal clusters that testing missed or confirmed clusters testing identified.
Create a dashboard showing production incidents by component. Update it monthly. The visual pattern will guide your testing strategy.
Listen to Developer Feedback
Developers know where the problematic code lives. They groan when they have to work on certain modules. They warn each other about “that tricky authentication flow” or “the payment processing mess.” These informal warnings indicate clusters.
Have explicit conversations with developers: “Which parts of this codebase are the most fragile? Where do you find the most bugs during development? What areas make you nervous?”
Observe Testing Patterns
Pay attention to your own testing experience. When you find a bug, do you immediately find three more in the same area? That’s a cluster. When certain features consistently fail testing while others pass cleanly, you’ve identified a pattern. When you groan seeing a particular feature on the test plan because you know it’ll be problematic, you’re recognizing a cluster.
Trust your testing intuition — it’s pattern recognition based on experience.
Real-World Example: The Payment Processing Cluster
Let’s examine a concrete example of defect clustering in action.
The Project
A mid-sized e-commerce company building a new checkout system. The development took twelve weeks with a team of eight developers and three testers. The system included product browsing, shopping cart, user accounts, payment processing, order management, and shipping integration.
The Discovery
During the first two weeks of testing, the team found defects spread across various features as expected. But by week three, a pattern emerged that became impossible to ignore.
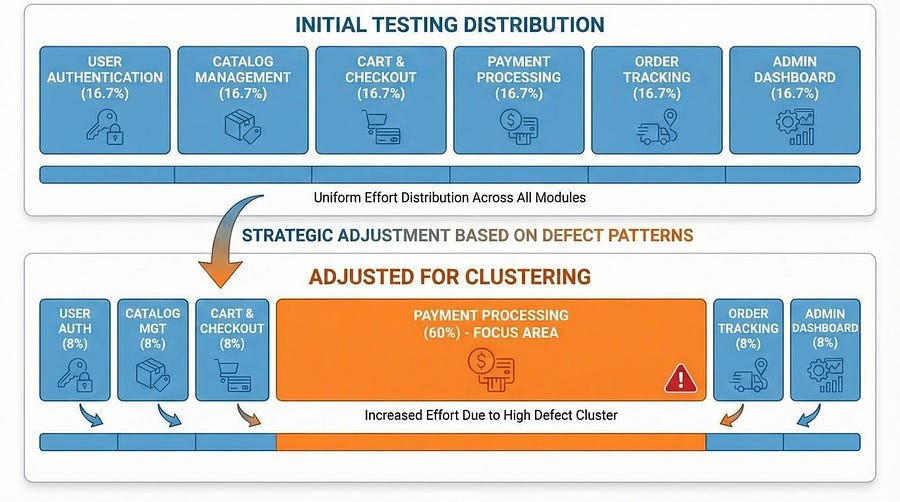
The payment processing module, which represented about fifteen percent of the total codebase, contained fifty-three of the seventy-two total defects found. That’s seventy-three percent of all bugs in fifteen percent of the code. The cluster was undeniable.
The Analysis
Why did defects cluster so heavily in payment processing? The team investigated and found multiple contributing factors working together.
First, the complexity was significantly higher than other modules. Payment processing involved integrating with three different payment gateways, each with different APIs and requirements. It handled multiple currencies and complex tax calculations. It dealt with security requirements like PCI compliance and tokenization. Error handling needed to be sophisticated because payment failures had serious consequences.
Second, this was the module under the most time pressure. Because payment integration was on the critical path and delayed by vendor API changes, developers rushed to catch up in the final weeks. Code reviews were abbreviated. Unit testing was incomplete. Technical debt accumulated rapidly.
Third, the team assigned less experienced developers to parts of the payment module because senior developers were needed elsewhere. These developers made predictable mistakes around error handling, edge cases, and security that more experienced developers might have avoided.
Fourth, the payment module had the highest change frequency. Requirements kept evolving as business stakeholders refined the user experience and added new payment methods. Each change introduced new opportunities for defects.
The Response
Once the cluster was identified, the team adjusted their strategy dramatically. They allocated sixty percent of remaining testing time specifically to payment processing instead of the fifteen percent proportional to its code size. They brought in a senior developer to conduct a thorough code review and refactor problematic areas. They added automated regression tests specifically for payment flows. They created a dedicated exploratory testing session focused entirely on payment edge cases. They implemented additional monitoring for the payment module in production.
The Outcome
The extra focus paid off. Testing found an additional thirty-two defects in payment processing before launch. While this might sound bad, it was actually good — these were bugs that would have reached customers otherwise. After launch, payment processing had one of the lowest production incident rates despite its complexity, specifically because the team recognized the cluster and responded appropriately.
Meanwhile, other features that had shown clean testing results remained clean in production. The testing effort was distributed based on where defects actually clustered, not evenly across all features.
What to Do When You Find a Cluster
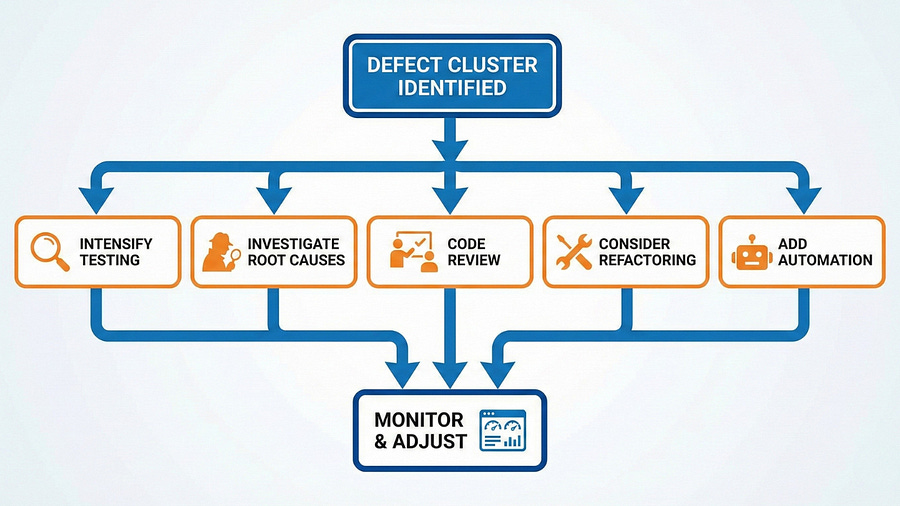
Identifying a defect cluster is just the beginning. Your response determines whether the cluster becomes a disaster or a learning opportunity.
Intensify Testing in the Cluster
The immediate response is increasing testing focus on the cluster area. Allocate more testing time proportional to defect density, not code size. Apply multiple testing techniques — functional testing, exploratory testing, security testing, performance testing — whatever’s relevant to that area. Create specific test sessions dedicated to the problematic module. Assign your most experienced testers to the cluster zones because complex, buggy code requires expertise to test effectively.
Don’t just run more of the same tests. If you found twenty defects with your current approach, you need different approaches to find the hidden bugs your current testing missed.
Look for Related Issues
When you find defects clustering in one area, look for related problems nearby. If authentication has many bugs, test session management, password reset, and user roles thoroughly — they’re likely part of the same problematic ecosystem. If one API endpoint is buggy, test other endpoints from the same service. If one calculation has issues, check related calculations.
Bugs travel in packs. Find one, and you should immediately widen your search radius.
Investigate Root Causes
Don’t just log bugs — understand why they’re clustering. Is the code overly complex and needs refactoring? Is there a fundamental design flaw that makes bugs inevitable? Are developers unfamiliar with the technology being used? Is time pressure causing rushed work? Are integration points poorly defined?
Have conversations with developers. Review the code. Examine the project history. Understanding why defects cluster helps you prevent clusters in future projects.
Consider Refactoring
Sometimes the right response to a severe defect cluster is stopping to refactor before continuing. If the code is so problematic that bugs keep appearing faster than you can fix them, you’re treating symptoms rather than disease. Refactoring might delay the project slightly, but it’s often faster overall than endlessly fixing bugs in fundamentally flawed code.
This is a difficult conversation to have with stakeholders, but data about defect clusters makes the case compelling. Show them the numbers. Explain that the current trajectory leads to a buggy release and ongoing maintenance nightmares.
Increase Code Review
Defect clusters benefit greatly from intensive code review. Have senior developers review clustered areas even if they weren’t originally assigned there. Consider pair programming for modifications to cluster zones. Require additional review levels before committing changes to problematic modules.
Code review finds different types of defects than testing finds. The combination is powerful.
Add Targeted Automation
Create automated regression tests specifically for cluster areas. Since these areas are defect-prone, they’re also prone to regression when you fix one bug and break something else. Automated tests catch regressions immediately instead of discovering them weeks later.
Build a safety net of tests around the fragile code.
Communicate the Pattern
Make defect clustering visible to the entire team. Create dashboards showing where bugs concentrate. Discuss clusters in team meetings. Help everyone understand which areas need extra care. When developers work on cluster zones, they’ll be more cautious. When testers plan their work, they’ll allocate time appropriately.
Transparency about quality patterns helps the whole team make better decisions.
The Pesticide Paradox Meets Defect Clustering
Remember Principle Five from our earlier articles: the Pesticide Paradox, which states that running the same tests repeatedly makes them less effective at finding new bugs. This principle becomes even more important when dealing with defect clusters.
Here’s what happens in practice. You identify a defect cluster in your payment processing module. You intensively test it, finding twenty bugs. You retest after fixes, running the same tests. They all pass. You feel confident. You ship. Then production reveals ten new bugs in the same module that your tests never caught.
Why? Because you kept running the same tests that found the first twenty bugs. Those tests became optimized for finding specific types of problems. The bugs that remained were different types — ones your test approach wasn’t designed to catch.
Breaking the Pattern
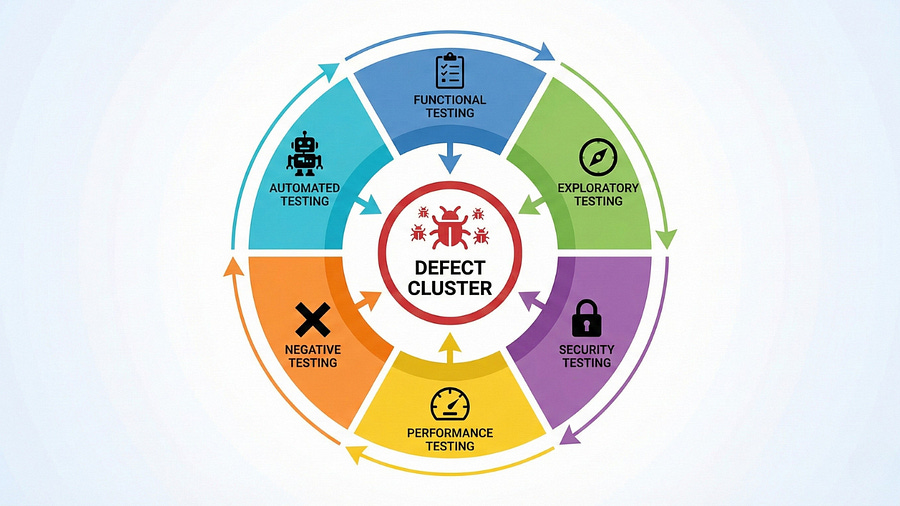
To effectively address defect clusters, you must continuously vary your testing approach. After finding bugs with functional testing, try exploratory testing. After exploratory testing, try security testing. After manual testing, try automated testing with different data sets. After positive testing, try negative testing. After testing happy paths, test error paths.
Defect clusters require testing creativity. The module that already has forty known bugs probably has forty more you haven’t found yet. Finding them requires thinking differently than you did to find the first forty.
Ask yourself: “What type of bug would this testing approach miss?” Then design tests specifically to catch those types.
Defect Clustering Across the Software Lifecycle
Defect clustering manifests differently at different stages of development.
During Requirements and Design
Clusters can appear even before coding begins. When requirements documentation has sections that keep getting modified, questioned, or clarified, that’s a cluster forming. When design reviews repeatedly return to the same architectural decisions with unresolved concerns, you’re looking at a future defect cluster. When stakeholders disagree about how certain features should work, those features will likely have defect clusters after implementation.
Pay attention to these early warning signs. Areas that are problematic during planning will be problematic during testing.
During Development
Developers know where clusters are forming in real-time. The code that takes three times longer to write than estimated is forming a cluster. The pull requests that generate extensive review comments are cluster candidates. The sections where developers keep finding and fixing bugs during unit testing signal clustering. The modules that cause build failures or test failures repeatedly are active clusters.
Development metrics can predict testing clusters before testing even begins.
During Testing
This is when clusters become most visible. You start testing Feature A and find two bugs. You test Feature B and find fifteen bugs. You test Feature C and find one bug. Feature B is your cluster. The pattern continues throughout testing — some areas consistently consume disproportionate testing effort while others are clean.
Track this data. It informs both current testing priorities and future project planning.
In Production
Production clusters are the most expensive to deal with. When customer support tickets concentrate on specific features, that’s a cluster. When production incidents consistently involve the same services, that’s a cluster. When hotfixes and emergency patches repeatedly address the same modules, you’re managing an active cluster.
Production cluster data should feed back into your testing strategy for future releases. If payment processing caused sixty percent of production issues, allocate sixty percent of testing effort there next time — before it reaches production.
Using Defect Clustering to Improve Risk Assessment
Defect clustering directly enhances the risk-based testing approach we discussed in the previous article. Historical defect data becomes one of your strongest predictors of future defects.
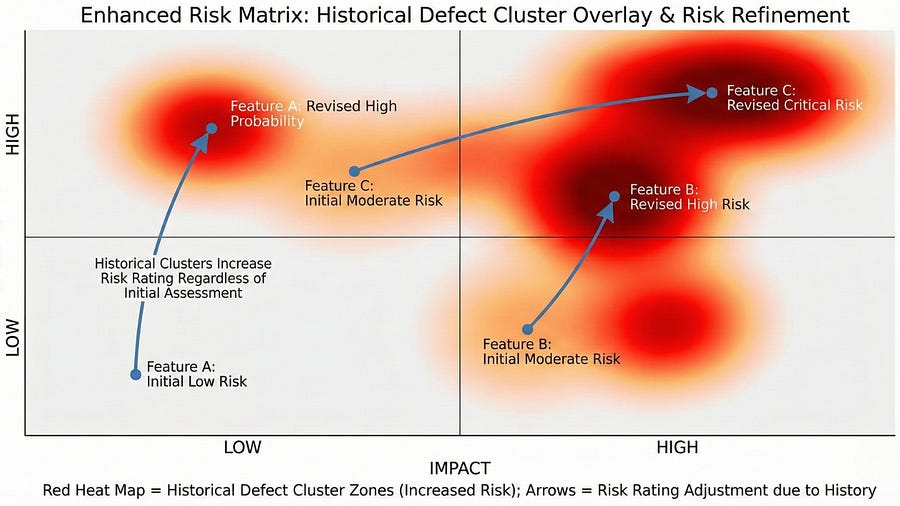
When assessing risk for a new feature or release, look at where defects clustered previously. The payment processing module that had fifty-three bugs last release will likely have high defect density next release too, especially if underlying complexity hasn’t changed. This historical pattern should increase your risk rating for that area.
Conversely, modules that consistently show clean testing and few production issues deserve confidence. You can allocate less testing effort there with justified reasoning based on data, not assumption.
Create a risk multiplier based on historical clustering. A feature assessed as medium risk that’s in a known defect cluster area might be elevated to high risk. A feature assessed as high risk that’s in a historically clean area might stay high risk but require less testing than a high-risk feature in a cluster zone.
Risk assessment becomes more accurate when you incorporate clustering data. You’re no longer guessing — you’re using evidence.
AI and Defect Clustering
AI tools can significantly enhance your ability to identify and respond to defect clusters, but they come with important limitations.
How AI Helps with Clustering
AI excels at pattern recognition in large datasets. It can analyze thousands of past defects and automatically identify clustering patterns that might not be obvious to humans looking at raw data. Machine learning models can predict where future defects will likely appear based on code complexity metrics, change frequency, and historical defect data. AI can monitor defect tracking systems in real-time and alert you when new clusters begin forming. It can correlate multiple factors — code complexity, developer experience, change frequency, integration points — to predict cluster likelihood with impressive accuracy.
Some AI tools analyze code repositories and highlight modules that match the characteristics of past defect clusters before you’ve even tested them. This predictive capability lets you preemptively allocate testing resources rather than discovering clusters through painful experience.
AI’s Limitations in Clustering Analysis
However, AI cannot understand context the way humans can. It might identify a statistical cluster that’s meaningless — perhaps a module has many low-severity cosmetic issues that don’t matter while another module has three critical security flaws that matter enormously. AI sees quantities but struggles with quality and context.
AI can’t explain why clusters form in human terms. It might tell you Module X has high defect probability, but it can’t tell you that’s because the developer was learning a new framework or because requirements changed five times during implementation. Understanding why matters for prevention.
AI also can’t make judgment calls about what to do with cluster information. Should you refactor, add testing, assign different developers, or accept the risk? These strategic decisions require human expertise considering business context, team dynamics, and project constraints.
Trust But Verify with Clustering
Use AI to surface patterns faster and more comprehensively than manual analysis could. Let AI process your defect tracking data, code metrics, and repository history to highlight potential clusters. But apply your expertise to interpret what AI finds. Investigate whether identified clusters are meaningful. Understand the context behind the patterns. Make strategic decisions about response.
AI accelerates defect cluster identification. You provide the wisdom about what to do with that information.
Preventing Future Clusters
While you can’t eliminate defect clustering entirely — complexity will always create risk — you can reduce cluster severity and frequency through intentional practices.
Design for Testability
When architectural decisions consider testability from the start, cluster formation decreases. Design systems with clear interfaces and boundaries that isolate complexity. Keep functions and classes small and focused so complexity doesn’t accumulate in single places. Build in observability so when things go wrong, you can understand what happened. Create modular architectures where components can be tested independently. These design choices don’t eliminate bugs, but they prevent bugs from multiplying in tangled code.
Invest in Code Quality
Code quality practices directly reduce clustering. Regular refactoring prevents complexity from accumulating into unmanageable masses. Code reviews catch issues before they become embedded problems. Static analysis tools identify complexity and quality issues early. Unit testing forces developers to write testable code, which tends to be simpler code. Technical debt management prevents the gradual degradation that leads to cluster formation.
High-quality code still has bugs, but fewer of them, and they’re easier to find and fix.
Manage Complexity Deliberately
Not all complexity is bad — some problems are inherently complex. But complexity should be isolated, managed, and well-tested. Identify complex modules explicitly and treat them as high-risk from the start. Allocate your best developers to complex areas. Provide extra time for complex features rather than rushing them. Build extra testing time into estimates for complex modules. Create focused documentation for complex logic. Consider pair programming for especially tricky code.
Acknowledge complexity honestly rather than pretending it doesn’t exist.
Learn from Past Clusters
Every defect cluster is a learning opportunity. After each project or release, conduct a cluster retrospective. Where did defects cluster and why? What could you have done differently to prevent or reduce the cluster? What early warning signs did you miss? How accurately did your risk assessment predict actual clusters? What testing techniques were most effective in cluster areas?
Document these lessons and apply them to future projects. Teams that learn from clustering patterns see fewer severe clusters over time because they recognize and address root causes.
Monitor for Emerging Clusters
Don’t wait until testing to discover clusters. Monitor during development for early signs. Track bug counts from unit testing by module. Watch which pull requests generate the most review comments. Notice which features take longer than estimated. Observe which areas developers complain about. Pay attention to frequent code changes in the same files.
These early indicators let you intervene before clusters become entrenched. You might add code review, refactor problematic code, bring in additional expertise, or adjust timelines before problems multiply.
Action Steps
Map your current project. If you have access to defect tracking data, create a simple spreadsheet counting defects by module, feature, or component. Sort by defect count. The clusters will be obvious. What do you notice about where bugs concentrate?
Investigate one cluster. Choose one area with high defect density. Research why bugs cluster there. Interview developers who work on that code. Review the code yourself if you can. Examine the module’s history. Is it complex? Frequently changed? Integrated with external systems? Developed under time pressure? Understanding why helps you test more effectively.
Compare with risk assessment. If you’ve done risk-based testing planning, compare your risk assessment against actual defect distribution. Did you predict the clusters accurately? Where were you wrong? What factors did you miss? Use this learning to refine your risk assessment approach.
Create a heat map. Visualize your project’s defect distribution. This could be as simple as a color-coded table or as sophisticated as a dashboard. Share it with your team. Make clustering patterns visible to everyone.
Track one metric over time. Choose a simple metric like “defects per module” and track it sprint over sprint or week over week. Watch how clusters form, grow, stabilize, or shrink. Understanding cluster dynamics over time helps you predict and respond to them.
Moving Forward
Defect clustering is one of the most reliable patterns in software testing. Once you learn to recognize clusters, you’ll see them everywhere. More importantly, you’ll know what to do about them.
The 80/20 rule in software quality isn’t just an interesting statistic — it’s actionable intelligence. When eighty percent of bugs live in twenty percent of your code, you know exactly where to focus your limited testing resources. You can justify strategic decisions about test allocation. You can predict where problems will appear. You can prevent clusters from forming in future projects.
Understanding defect clustering transforms you from someone who reacts to bugs into someone who anticipates and prevents them. Combined with risk-based testing from our previous article, you now have a comprehensive framework for strategic testing that maximizes quality within real-world constraints.
In our next article, we’ll explore Context-Dependent Testing — why there’s no one-size-fits-all approach to testing and how to adapt your strategy based on project context. This builds naturally on what we’ve learned: if defects cluster differently in different types of projects, our testing approach must adapt to context. A payment processing module in a banking app demands different testing than a payment module in a casual gaming app, even though both process payments.
Remember: Bugs cluster. Test accordingly.